Data Architecture: Definition, Evolution & Characteristics
Data serves as the understructure of every decision-making process and business operation. To effectively manage, process, and utilize this valuable resource, organizations rely on data architecture — a strategic framework that defines how data is collected, stored, integrated, and utilized.
This article steps into the essence of data architecture, exploring its significance in maintaining seamless workflows and driving innovation. We will examine the importance of data architecture, its defining characteristics, nd its guiding principles. Additionally, we’ll explore popular frameworks that serve as blueprints for designing robust data systems and analyze the phases of a well-structured data architecture lifecycle.
What is Data Architecture?

Data Architecture is a framework of models, policies, rules, and standards that an organization uses to manage data. Data Architecture standardizes data usage processes such as storing, transforming, and serving data, helping users easily access frequently updated data.
Data Architecture needs to be consistent with the organization's data flow. The person building the Data Architecture must determine exactly how to distribute data to meet the needs and create the most value.
The Evolution of Data Architecture
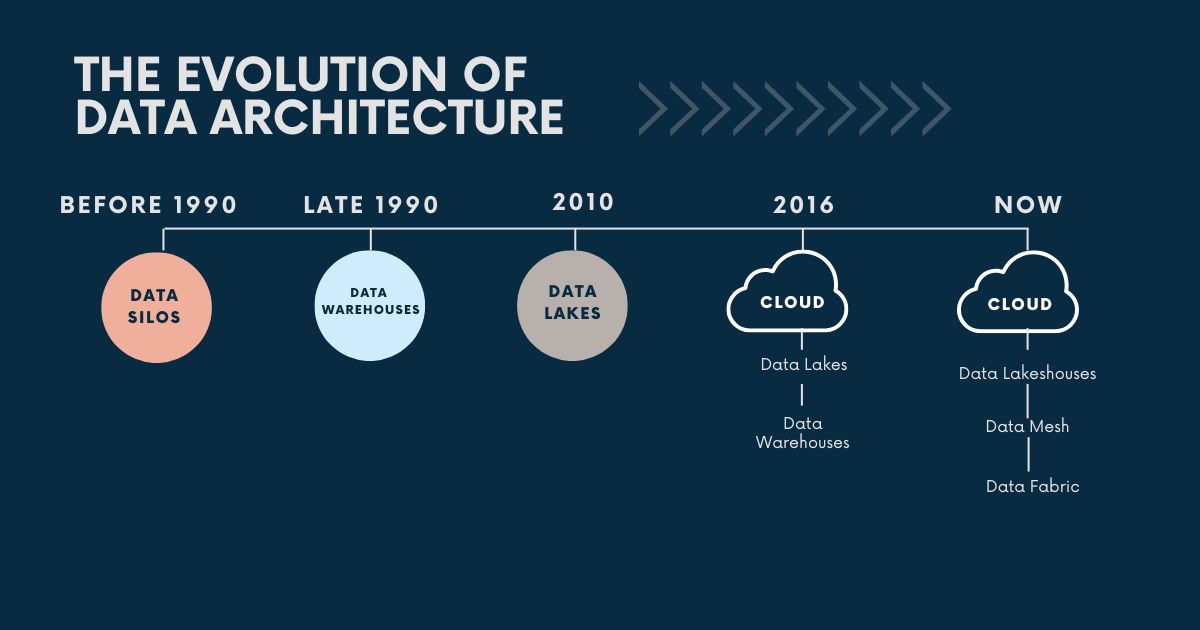
The evolution of data architecture offers structured approaches to managing data throughout its lifecycle.
Phase 1: Data Warehouse Architecture
Data warehouse architecture collects and extracts data from many different data sources and databases (Extraction - E), then performs cleaning and transformation techniques (Transform - T) to model data into data loads imported (Load - L) into the data warehouse to serve Business Intelligence (BI) tools and data science models.
Building a data warehouse is the process of synthesizing data from many operating systems, third-party applications, IoT devices, social networks, etc. (for example, data created during the Sales process of attracting and caring for customers, through SAP, Salesforce tools). The data warehouse is the center, designed in the form of a snowflake schema or star schema.
Data is processed, cleaned, transformed, and stored in dimension tables or fact tables to create a Relational Database Management System (RDBMS). Based on that, businesses can use data to quickly create reports, dashboards to track activities and interactions at many customer touchpoints.
The biggest challenge of this approach:
Over time, the ETL workload, the number of data tables and reports built for a specific group of users increase and need to be maintained.
Modern engineering practices such as CI/CD are not applied.
If the data model and schema design for the data warehouse are too rigid, the Data Analyst will have to process large amounts of structured and unstructured data from multiple sources.
Loading data in batches at specific intervals is still common, but many organizations require continuous loading (micro batching) and instant loading.
Scaling the data warehouse to meet increasing storage and workload needs can be expensive, difficult, and burdensome to the system's performance.
These challenges pave the way for the next phase of data architecture.
Phase 2: Data Lake Architecture
Data lake architecture was first introduced in 2010 to overcome the challenges posed by data warehouses and to meet new uses for data: helping Data Scientists access raw data in its original format during the training process for machine learning models. Data lake architecture is an approach to designing a centralized place to store raw data in its original format without predefined and designed schemas.
Data lake architecture operates according to the ELT process instead of ETL: Data will be extracted (Extracted – E) from operational systems, then loaded (Loaded – L) into a central repository.
However, unlike data warehouses, data after being put into the data lake is not (or very little) transformed, cleaned, and modeled. In this raw data storage "area," organizations can use big data storage solutions such as Hadoop HDFS, Amazon S3, or Azure Blob Storage. From the data lake, data will go through data transformation pipelines (T) to model raw data and store it in the data warehouse.
The data from here will be transformed:
Data cleansing removes inaccurate, malformed, duplicate, irrelevant, incomplete, inconsistent, unnormalized, or dirty data in the database.
Data enrichment: adds value to the original dataset by combining data or adding context.
After these transformation steps, the data is considered trustworthy and can be used for analysis and training of predictive models.
Thus, with the data lake architecture:
Improves the inefficiency and flexibility of comprehensive modeling from the beginning of the process that a data warehouse requires. The flexibility in storage allows DA and DS to access raw data, which is the input for problems, predictive models, or ML projects, overcoming the problems of data warehouses in performance and speed of processing large data. Transforming data early is considered a hindrance and leads to loops that make the process of accessing data and training models slower.
Advantages in data backup and recovery thanks to the ability to scale at low cost.
Working with many different data types, from structured data, semi-structured data, and unstructured data.
Data sources:
- Structured data sources: Structured data is organized data, usually in the form of a data table with a column structure of attributes defined in a structured database – relational database (RDBMS). Some structured database management systems include SQL databases such as MySQL, Oracle, and Microsoft SQL Server. This is also the reason why SQL is a structured query language.
- Semi-structured data sources: This type of data has been organized but does not really meet the basic data normalization conditions (1NF, 2NF, 3NE, BCNF). Using JSON data fields can free up space in the database table and reduce the number of records, but to have structured data, DA still needs additional steps to convert data.
- Unstructured data sources: Unstructured data is data that does not have a pre-defined structure. For example, sensor data in Internet of Things (IoT) applications, video and audio streams, images, and social media content such as tweets or Facebook posts, etc.
Data ingestion via multiple protocols such as APIs and connectors ensures smooth data flow, responding to the heterogeneous nature of data sources with a variety of methods:
- Batch ingestion: This data ingestion method operates on a time schedule. For example, a DE can set the system to run overnight every day to transfer large volumes of data at once. Commonly used tools for batch ingestion include Apache NiFi, Flume, and traditional ETL tools such as Talend and Microsoft SSIS.
- Streaming (data flow to load data as close to real-time as possible): This method will immediately bring data into the data lake when the record is created. The close to real-time factor is important for fraud detection or analytics that need to be available immediately. Tools that support this data ingestion method include Apache Kafka and AWS Kinesis.
The biggest challenges of this approach:
Batch or stream data delivery methods also require high-level data engineer (DE) skills and expertise
The data lake architecture becomes complex and devalued if the data quality is poor or unreliable. Unstructured data can also lead to problems such as unmanaged data, unusable data, etc. This process can lead to datasets that are out of control and management, which can eventually lead to unreliable models, lack of reuse, and provide little value
Centralized architecture design requires a team of highly skilled Data Engineers
Data lineage (when data becomes an input source for reports, dashboards, and is used in different departments, workspaces) and data visualizations are also difficult to control and monitor
The biggest risk of data lakes is security and control. The lack of data modeling at the outset also makes it difficult to build a semantically meaningful mapping between different data sources, and the data stored is not identified for cataloging and security, resulting in a “data swamp” (mixing both usable data and “garbage” data).
So what is the difference between a data warehouse and a data lake?
| Data Lakes Architecture | Data Warehouse Architecture | |
| Storage | Data lakes store all data | Data warehouse stores data that has been organized according to a schema |
| Data type | Structured data, Semi-structured data, Unstructured data | Mainly stores structured data in tables |
| Schema | Schema-on-reading (schema is not pre-defined) | Schema-on-write (schema is pre-defined) |
| Data processing | ELT (data transformation after data is loaded from the data lake) | ETL (data transformation immediately before data is loaded) |
| Optimized for | Flexible storage and processing capabilities | Query performance |
Phase 3: Cloud Data Lake Architecture
The transition between the second and third stages of data architecture is from storing data on an internal physical infrastructure system to storing data on the cloud – characterized by real-time data availability and some common characteristics from data warehouses and data lakes.
The cloud is the most important factor with the ability to create access to virtually unlimited open resources; increase flexibility by taking full advantage of tools in the cloud ecosystem (e.g. AWS, GCP, and Microsoft Azure); separate computing and storage capabilities; reduce hardware infrastructure costs – businesses will pay based on data storage and processing resources, software provided and data management as well as security systems.
Increasing the ability to unify batch processing and processing streams to transform data using tools such as Apache Beam.
Data warehouse and data lake are gathered in one technology: expanding data warehouse by integrating (1) data retrieval capabilities in integrating machine learning model training, (2) still ensuring the integrity and innovation of transaction data updates, and (3) the ability to query the system with the characteristics of data lake architecture.
Solid state drives (SSDs): Unlike hard disk drives (HDDs), SSDs store data on flash memory chips, which helps speed up data storage, retrieval, and analysis.
The node system allows a large number of users to have access to the same data system, at the same time without reducing performance. Data loading and querying can take place simultaneously.
Resiliency is the ability of a data warehouse to continue operating automatically when a component, network, or even data center fails.
Phase 4: Data Mesh Architecture
Data mesh architecture is a relatively new and still in its infancy approach to data architecture. It seeks to address some of the challenges identified in previous centralized architectures.
Data mesh is a data architecture organized in a microservice-like manner, distributed and oriented to serve each domain that can be independently queried according to different business products and use cases. Microservice can be understood as an application in the form of a collection of small services that are combined. Each service runs in its own process and can be deployed independently with a very lightweight protocol.
With data mesh architecture, data can be kept raw or transformed in a centralized or decentralized direction, and ownership is assigned to each domain.
Each domain will be autonomous in data and perform different cross-analytic techniques according to the needs and problems of its team, including receiving operational data, modeling, designing entities, schemas (data design), storing and governing data effectively as a separate asset, while providing practices so that each domain can independently manage and exploit data, democratizing.
The transition from monolithic applications to microservice applications has forced software engineering teams to change their development lifecycle, organizational structure, motivation, skills, and governance. That is when the role of the Product Manager appears to ensure that applications will solve real user problems. Data needs to be used to solve real problems and questions of domain end-users during the operation process.
This concept is different from data mart in data warehouse architecture in that: data mart is designed to serve many different teams, for example, data mart with grain as customer (dim_customer) is used to build reporting and dashboard systems for both marketing and sales teams; while with data mesh architecture, data will be designed specifically for the sales team, with many domains, depending on the focus area that the team is aiming for.
Some characteristics of the data mesh architecture
Data Products: Each domain plays the role of producing, owning, and utilizing knowledge of the field and data problems to package data, design APIs (for example, Stripe payment gateway API solves the payment problem of E-Commerce, Trello API solves the task management problem of Human Resources, etc. These APIs can be accessed from other departments).
Data Infrastructure: A system of tools and technologies that help manage the data of a domain, similar to packaged services for software applications.
Data Governance: A set of processes to manage data quality, privacy, and security, including assigning data access rights to users, packaging data dictionary documents, policies to ensure data quality, or building alerts when data is redundant or missing compared to the data source, etc.
Mesh API: Mesh API displays data in a clearly defined structure that other domains and data products can use. Data Product APIs will be followed by HTTP REST APIs and mesh data catalogs.
The Data Team is now required to work flexibly, multi-functionally, and understand the data and operations of multiple fields and departments (cross-functional), including both business and technology blocks, similar to a software product group following a service orientation towards end users.
The term mesh appears when departmental teams use data products of other domains. Domains considered “upstream” such as the Checkout domain will provide order data or customer data that will be used by “downstream” domains – domains that are operational in nature of a business – such as the Fulfillment, Shipping department, or as input for CRM systems and other analytical systems.
Importance of Data Architecture

Data architecture is critical in shaping how organizations collect, store, process, and utilize data. As the volume, variety, and velocity of data increase, having a well-structured data architecture is essential for achieving efficiency, scalability, and strategic decision-making. Below are the key reasons why data architecture is crucial:
Enables Strategic Decision-Making
A robust data architecture facilitates that organizations can access reliable and timely data to make informed decisions. Data architecture maintains data accuracy and eliminates the risks associated with poor-quality data in strategic planning. This framework empowers leaders to base their decisions on solid, factual insights.
Supports Scalability
A well-structured data architecture can grow with the organization, accommodating increasing volumes and diverse types of data without sacrificing performance. It integrates modern technologies such as cloud computing, big data platforms, and machine learning, equipping the organization future-ready.
Improves Data Governance and Compliance
Data architecture enforces stringent rules for managing data, including security, privacy, and access control. It must comply with regulatory requirements like GDPR and HIPAA. It also defines data ownership and accountability, helping organizations maintain the integrity of their data assets.
Enhances Operational Efficiency
Optimized data architecture reduces silos, supporting teams to collaborate effectively across departments. It streamlines processes by facilitating faster data retrieval and minimizing latency in operational systems.
Drives Innovation
With a structured approach to managing data, organizations can adopt advanced technologies like artificial intelligence, predictive analytics, and IoT. This foundation accelerates the development of innovative solutions. Based on that, businesses can identify trends and uncover new opportunities.
Reduces Costs
A well-designed data architecture minimizes redundancy, unnecessary storage, and processing overheads, leading to significant cost savings. Additionally, automating workflows and reducing manual interventions lowers error rates as well as operational expenses.
Promotes Data Democratization
Data architecture creates user-friendly tools and interfaces. So, non-technical employees can access and utilize data effectively. This approach promotes a culture of data-driven decision-making and empowers teams to independently act on insights.
Facilitates Integration
A unified data architecture seamless integration of various data sources, systems, and tools, maintaining consistency across the enterprise. It supports interoperability between legacy systems and new technologies, making smooth transitions during upgrades or migrations.
Characteristics of Data Architecture

The characteristics of data architecture define its ability to meet organizational goals while addressing challenges related to data management. You should incorporate these traits to build robust, scalable, and secure systems that foster innovation, efficiency, and growth.
Data Centralization and Decentralization
Data architecture balances centralization and decentralization by defining whether data is stored and managed in a centralized repository, such as a data warehouse, or distributed across multiple systems, like a data mesh. This balance depends on the organization’s needs for control, accessibility, and scalability.
Data Integrity and Quality
You should know that data consistency, accuracy, and reliability are a cornerstone of data architecture. It establishes processes for data validation, deduplication, and standardization. This results in users across the organization can trust the data.
Flexibility and Scalability
A strong data architecture is designed to accommodate growth. It supports the addition of new data sources, tools, and technologies without disrupting existing operations. So, organizations easily scale seamlessly as their needs evolve.
Data Governance and Security
Effective data architecture integrates governance frameworks to define roles, responsibilities, and policies for data management. It enforces strict security protocols, such as encryption and access controls. The purpose of this feature is to safeguard sensitive information and compliance with regulatory standards.
Interoperability
Different systems, platforms, and tools can interact seamlessly with data architecture. Data architecture can use standardized data formats, protocols, and APIs. It facilitates the integration of diverse technologies and supports collaboration across departments.
Real-Time Data Processing
Modern data architectures often incorporate real-time or near-real-time data processing capabilities. This characteristic is crucial for applications like fraud detection, customer behavior analysis, and operational monitoring. In these cases, timely insights are essential.
Data Lifecycle Management
Data architecture defines how data is created, stored, accessed, updated, and retired. It efficiently manages the data lifecycle, optimizing storage and processing resources while maintaining compliance with data retention policies.
Resilience and Redundancy
Data architecture can recover from failures, such as hardware malfunctions or network outages. It incorporates redundancy and failover mechanisms to minimize downtime and protect critical data assets.
User-Centric Design
A well-designed data architecture prioritizes usability, providing tools and interfaces that enable both technical and non-technical users to interact with data easily. It supports self-service analytics and democratizes access to insights.
Support for Advanced Analytics
Data architecture supports advanced analytics by integration with machine learning models, AI frameworks, and big data processing tools. It offers the necessary infrastructure to analyze structured and unstructured data efficiently.
Principles that Data Architecture Must Follow
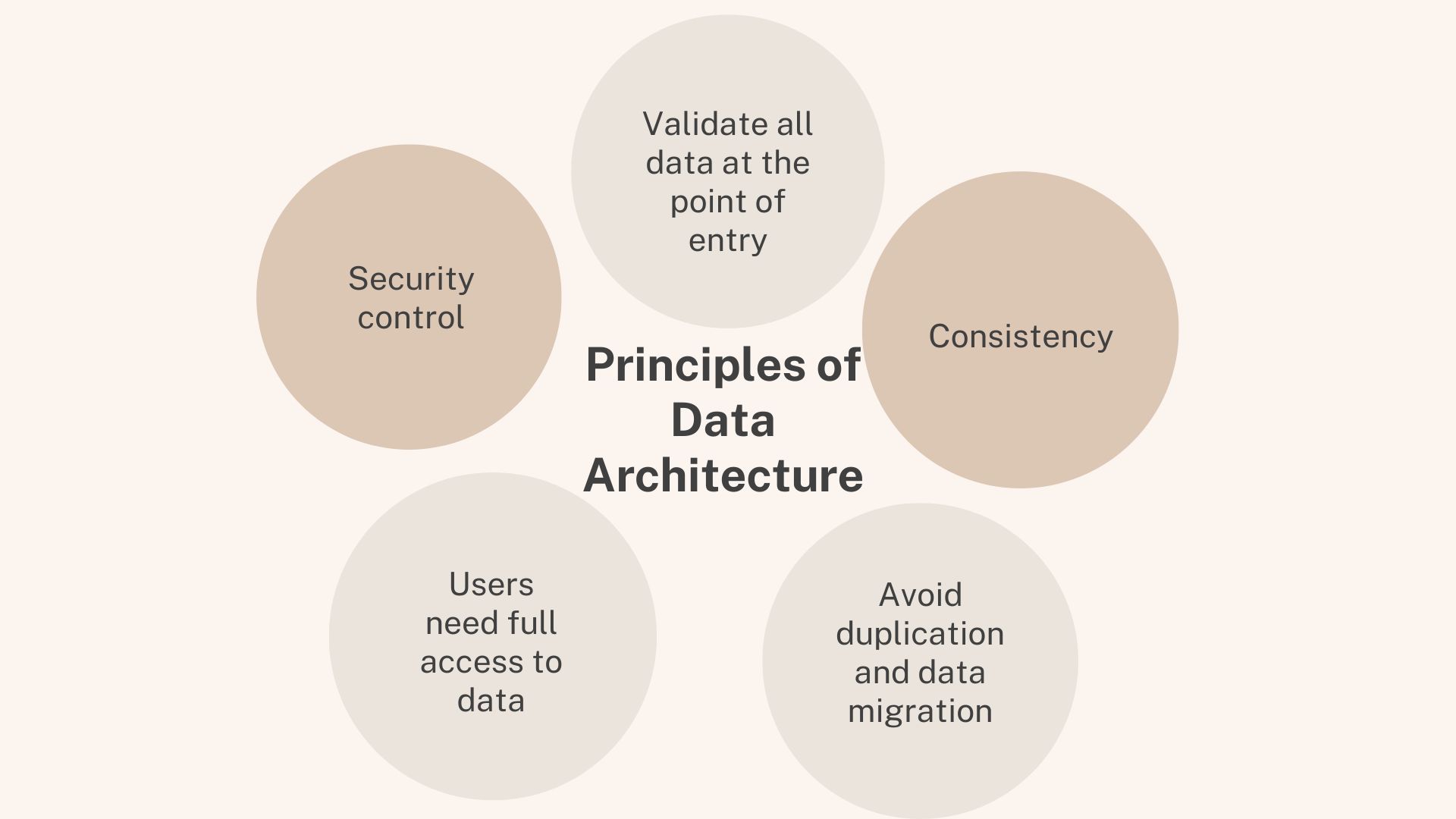
The principles of Data Architecture revolve around the issues of collecting, using, managing, and integrating data.
Validate all data at the point of entry
Improve the health of the organization's data by eliminating redundant data and correcting common data errors. Therefore, at the time of entry, Data Architecture needs to be designed to validate data as soon as possible. Any bad data or any errors detected need to be removed immediately.
Consistency
Use a “common language” for Data Architecture to be consistent in the way of working in the organization.
Avoid duplication and data migration
Data migration affects costs, accuracy, and time. Therefore, modern versions of Data Architecture always try to reduce the need for additional data migration, create fresh data, and optimize data flexibility.
Users need full access to data
Data Architecture is designed to help people get and use data in a reasonable process. Therefore, if users cannot access the data, this will be meaningless.
Security control
In addition to the above, not everyone can access the confidential data of the organization. To avoid information leakage, there should be hierarchy and access control for each data file, depending on their importance.
Popular Data Architecture Frameworks
Data Architecture Frameworks are used as a foundation for building an enterprise's Data Architecture.
DAMA-DMBOK 2
This refers to the DAMA International Data Management Body of Knowledge – a framework specifically designed for data management. It includes standard definitions of data management terminology, functions, distributions, roles and also presents guidelines on data management principles.
Zachman Framework for Enterprise Architecture
John Zachman created this enterprise ontology at IBM in the 1980s. The 'data' column of this framework includes several layers, such as the main architectural standards for the enterprise, the semantic model or conceptual data/enterprise model, the logical or enterprise data model, the physical data model, and the actual database.
The Open Group Architecture Framework (TOGAF)
TOGAF is the most widely used enterprise architecture methodology, providing a framework for designing, planning, implementing, and managing data architecture best practices. It helps define business goals and align them with architectural goals.
Check out the course. Please click on the course name below to learn more:
[2024] Mastering Data Modeling: Concept to Implementation
– Equip yourself with the mindset to transform and build a data system. In this course, you'll embark on a journey through the fundamental principles and advanced techniques of data modeling, from conceptualization to implementation.
Imbalanced Learning (Unbalanced Data) - The Complete Guide
This is a niche topic for students interested in data science and machine learning fields. The classical data imbalance problem is recognized as one of the major problems in the field of data mining and machine learning. Imbalanced learning focuses on how an intelligent system can learn when it is provided with unbalanced data.
Data-Driven Business: Experiment, Prototype & Improve
This comprehensive program guides you through the fascinating world of data-centric decision-making, and it is designed to intrigue and educate learners at any stage in their professional journey.
Conclusion
Data Architecture is increasingly being applied to many fields. Many operations have recognized the importance of data and have quickly promoted the construction – storage – exploitation of data in management and operation.
If you still want to know more about useful data knowledge, you can register for Skilltrans courses today!

Meet Hoang Duyen, an experienced SEO Specialist with a proven track record in driving organic growth and boosting online visibility. She has honed her skills in keyword research, on-page optimization, and technical SEO. Her expertise lies in crafting data-driven strategies that not only improve search engine rankings but also deliver tangible results for businesses.



